Unter Verwendung des hetida designer, unserem interaktiven Python Workflow-Editor, entwickeln wir ein Modell zur Prognose des Stromverbrauchs eines Industrieunternehmens. Neben der praxisbezogenen Fragestellung stehen insbesondere die Einsatzmöglichkeiten und die Bedienung des hetida designer im Vordergrund.
Einleitung und Fragestellung
Nicht nur Industrieunternehmen, sondern auch Stadtwerke, kaufen ihren Strom teils Jahre im Voraus an den Finanzmärkten ein. Je genauer der Verbrauch dabei für einen bestimmten Zeitpunkt prognostiziert werden kann, desto besser. Es werden weniger kurzfristige und teure Nachkäufe nötig. Umgekehrt muss nicht zu viel bereits eingekaufter Strom zu schlechteren Konditionen wieder verkauft werden.
Intuitive Faktoren bzw. Fragen neben der Uhrzeit, die den Stromverbrauch beeinflussen (können) sind:
Welcher Wochentag wird betrachtet? Fällt der Tag auf ein Wochenende?
Sind an diesem Tag Schulferien?
Handelt es sich um einen Feiertag?
Wir betrachten den Lastgang eines produzierenden Unternehmens im Schweizer Kanton Aargau im Jahr 2016. Dieser beinhaltet viertelstündliche Stromverbrauchswerte. Ausgehend von diesen Daten beantworten wir folgende Frage:
Wie hoch ist der Stromverbrauch des Unternehmens am 25. Mai 2017 in der Zeit von 10 bis 11 Uhr?
Für die Vorhersage des Stormverbrauchs arbeiten wir mit dem hetida designer. Wir beginnen unsere Analyse mit der Visualisierung der vorliegenden Daten. Im nächsten Schritt, der Datenaufbereitung, erweitern wir den Datensatz um die oben genannten zeitlichen Einflussfaktoren. Anschließend trainieren wir ein Modell, das den Lastgang aus dem Jahr 2016 möglichst exakt rekonstruiert. Hierzu betrachten wir die Lineare Regression und einen Random Forest Algorithmus, ein Machine Learning Basiswerkzeug. Schließlich verwenden wir den Random Forest Algorithmus, trainiert auf den Daten des Jahres 2016, zur Vorhersage für den 25. Mai 2017.
Visualisierung der Daten
Abbildung 1: Plot des Lastgangs aus dem Jahr 2016.
Auszumachen ist die für ein Industrieunternehmen typische fünf Tage Woche. Mitunter, beispielsweise im Mai, Juli, oder Ende Dezember, lassen sich abweichende Strukturen ausmachen. Diese wollen wir zunächst ergründen, erklären und dann in der Prognose für das Jahr 2017 berücksichtigen.
Abbildung 2: Workflow zur Visualisierung des Lastgangs. Zunächst werden die Daten als Time Series aus der Datenbank eingelesen (siehe Abbildung 3) und in einen Data Frame umgewandelt. Gleichzeitig werden die Stromverbrauchswerte mit dem Namen 'Values' versehen. Die zweite Komponente plottet die Daten.
Abbildung 3: Einlesen der Daten aus der Datenbank.
Datenaufbereitung
Jedem Verbrauchswert ordnen wir den entsprechenden Monat, den Wochentag und die Stunde im Tagesverlauf zu. Zur genaueren Analyse der zugrundeliegenden Zeitangaben wählen wir eine Darstellung mittels Sinus und Cosinus. Diese ermöglicht es, zyklische Abhängigkeiten zwischen den jeweiligen Zeitangaben gezielt zu berücksichtigen. Außerdem entscheiden wir für jeden Wert, ob dieser auf ein Wochenende, einen Feiertag oder einen Tag der Schulferien fällt. Der so generierte Datensatz bildet die Grundlage zur Entwicklung eines Modells zur Vorhersage des Stromverbrauchs für den 25. Mai 2017.
Abbildung 4: Datenaufbereitung mit dem hetida designer. Der oben generierte Data Frame wird zunächst um die zyklische Darstellung der Zeitangaben erweitert (Circular Representation of Time Components). Anschließend wird die Information hinzugefügt, ob ein Verbrauchswert auf ein Wochenende fällt (Weekend). Die drei weiteren Komponenten entscheiden, ob ein Wert auf einen Tag der Schulferien, einen Feiertag, oder sowohl auf ein Wochenende als auch einen Feiertag fällt. Diese drei Komponenten können für beliebige geographische Regionen verwendet werden, unter jeweils spezifischen Inputs. Für unser Unternehmen aus der Schweiz wählen wir beispielsweise “country = CH, province = AG, state = None, year = 2016”.
Lineare Regression
Neben der Regression der Verbrauchswerte ist für das zugrundeliegende Unternehmen vor allem von Interesse, wie gut das Modell den Lastgang abbildet. Die Güte des Modells analysieren wir dabei mit dem R²-Wert. Außerdem lassen wir die Koeffizienten der Einflussvariablen ausgeben, um einen Eindruck zu bekommen, welche dieser Faktoren einen besonders starken Einfluss auf den Stromverbrauch haben.
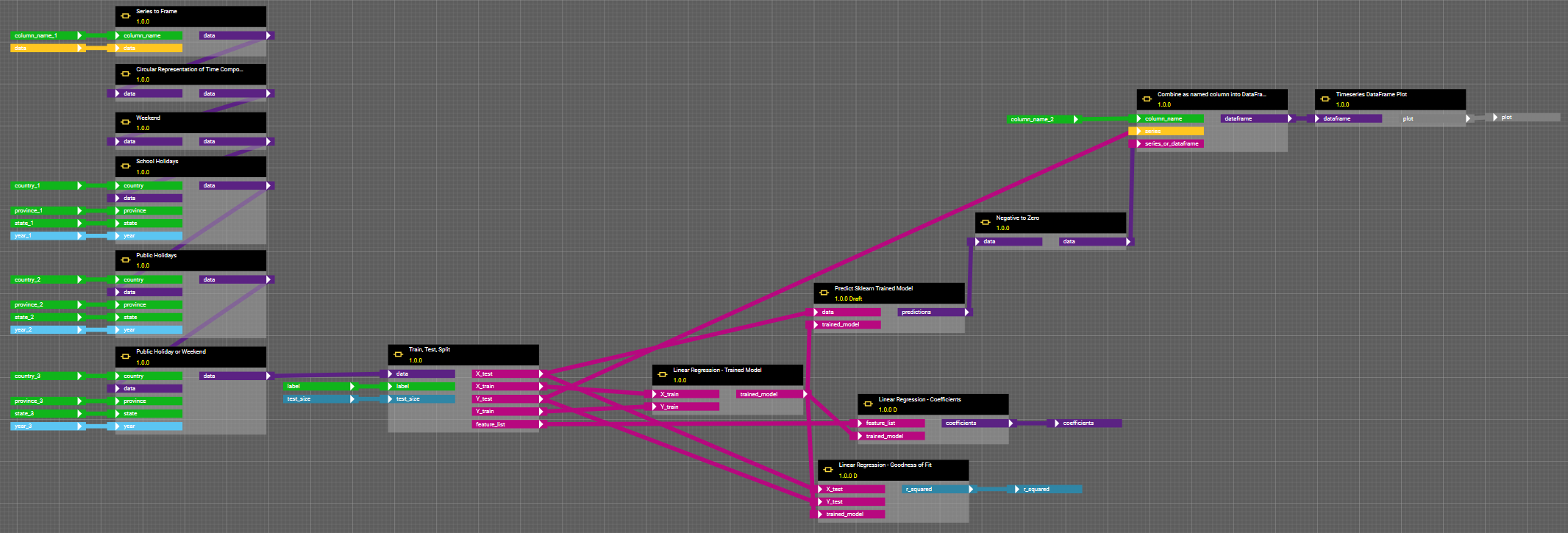
Abbildung 5: Workflow der gesamten Linearen Regression. Die aufbereiteten Daten werden zunächst für die Regression vorbereitet ('Train, Test, Split'). Hierzu werden die Daten in Trainings- und Testdaten aufgeteilt. Als Zielvariable (label) der Regression übergeben wir die Spalte ‘Values’. 20 Prozent der Daten (test_size = 0.2) wählen wir als Testdaten, auf den übrigen 80 Prozent wird das Modell trainiert. Dieses Trainieren erfolgt im nächsten Schritt ('Linear Regression - Trained Model'). Im oberen Strang des Workflows werden auf dem trainierten Modell daraufhin Vorhersagewerte generiert ('Predit Sklearn Trained Model'). Vereinzelt kann die Regression negative Werte prognostizieren. Da dies inhaltlich keinen Sinn macht, setzen wir diese Werte auf Null ('Negative to Zero'). Schließlich werden die vorhergesagten Werte zusammen mit den Testdaten visualisiert. Die unteren beiden Komponenten generieren die Koeffizienten ('Linear Regression - Coefficients') und den R²-Wert ('Linear Regression - Goodness of Fit') der Linearen Regression.
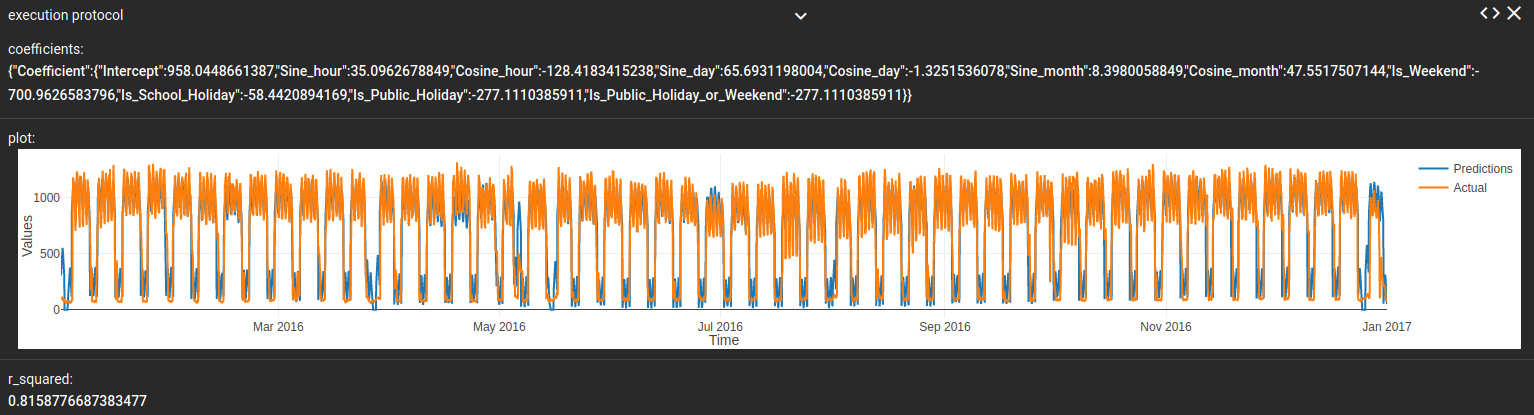
Abbildung 6: Das Ergebnisprotokoll nach Ausführung des obigen Workflows.
Wie zu erwarten, sind die Koeffizienten hinsichtlich Wochenende, Schulferien und Feiertagen stark negativ. An einem solchen Tag wird in dem Unternehmen deutlich weniger Strom verbraucht (siehe auch Abbildung 1). Diese Information ist insbesondere für die spätere Vorhersage von großer Wichtigkeit. Der R²-Wert ist mit 0.82 bereits im sehr guten Bereich.
Die Frage lautet: Sollten wir die Lineare Regression nun zur Vorhersage für den 25. Mai 2017 verwenden? Oder können wir das Modell beziehungsweise den R²-Wert noch weiter verbessern?
Random Forest
In einem zweiten Schritt übergeben wir den aufbereiteten Datensatz aus dem Jahr 2016 an einen Random Forest Algorithmus. Die Güte des Modells analysieren wir abermals mit dem R²-Wert. Zudem lassen wir den prozentualen Einfluss der Einflussvariablen in absteigender Reihenfolge ausgeben.
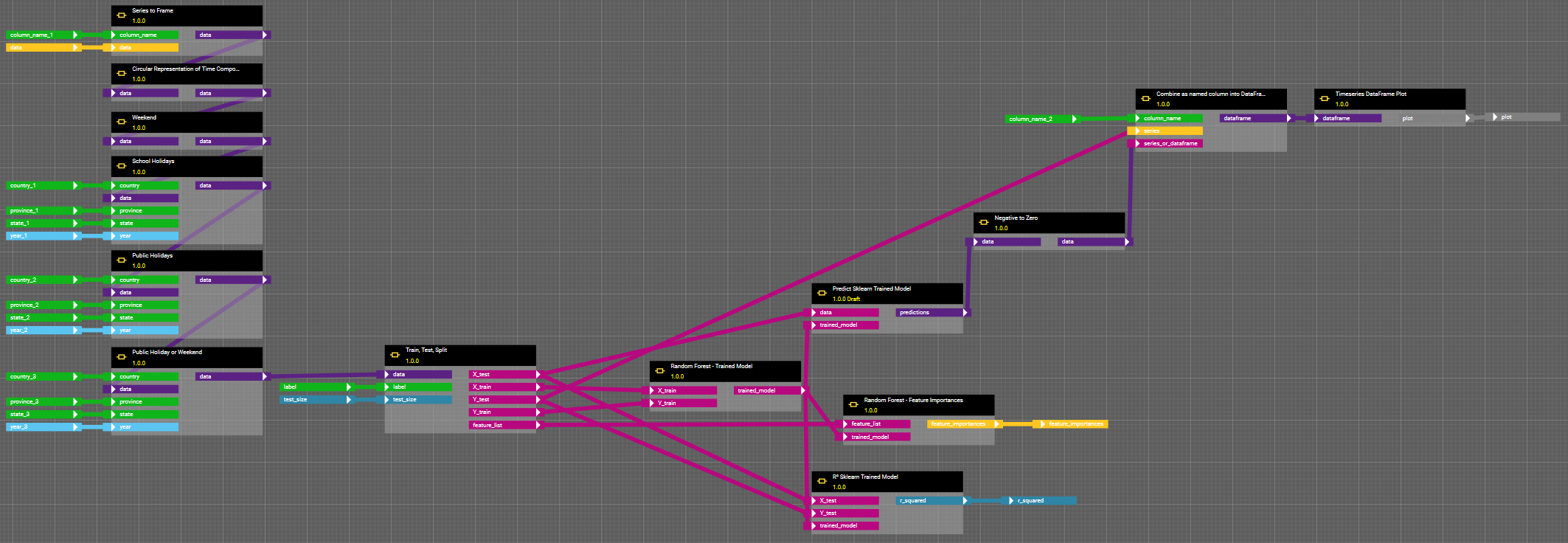
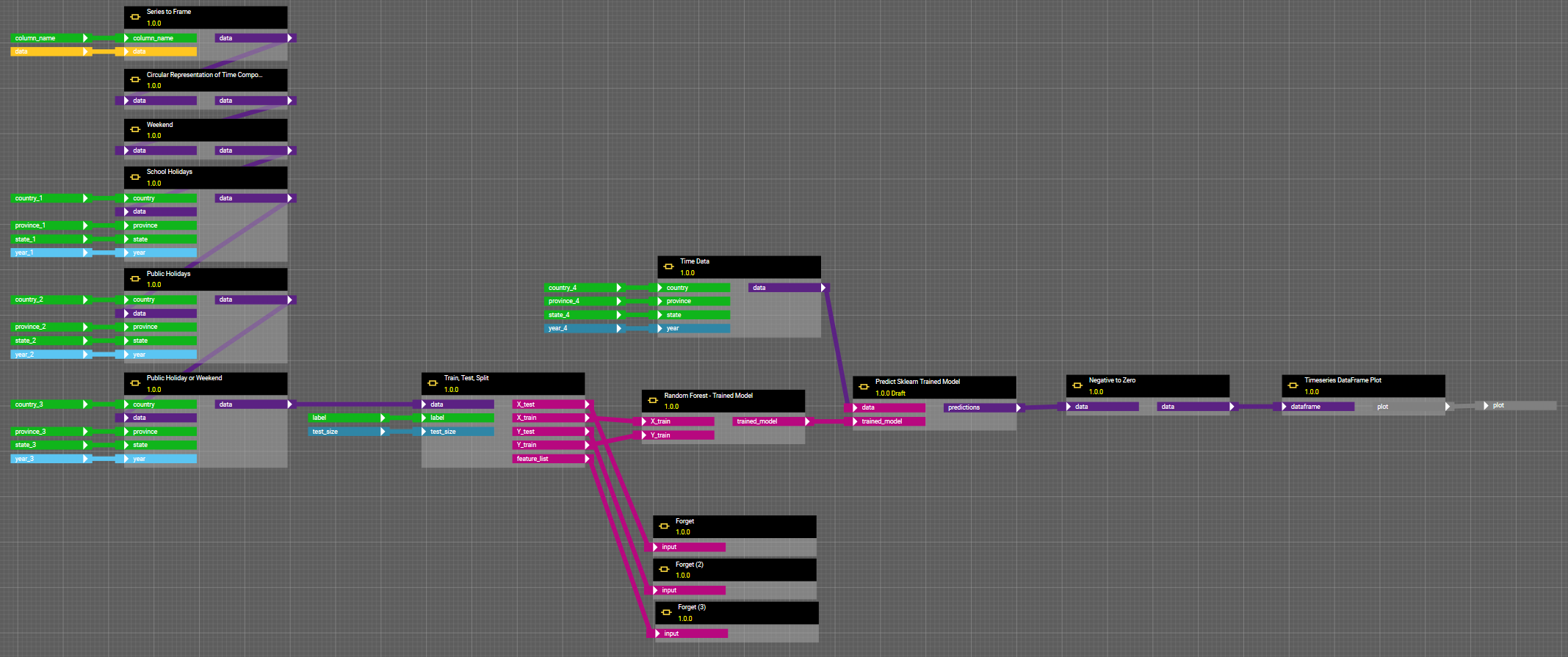
Abbildung 7: Workflow des Random Forest. Die Komponenten haben die gleichen Funktionalitäten wie bei der Linearen Regression (siehe Abbildung 5). Während zuvor jedoch die Koeffizienten der Einflussvariablen selber ausgegeben wurden, liefert der Random Forest gezielte Informationen darüber, wie stark deren Einfluss auf die Zielvariable, den Stromverbrauch, ist.
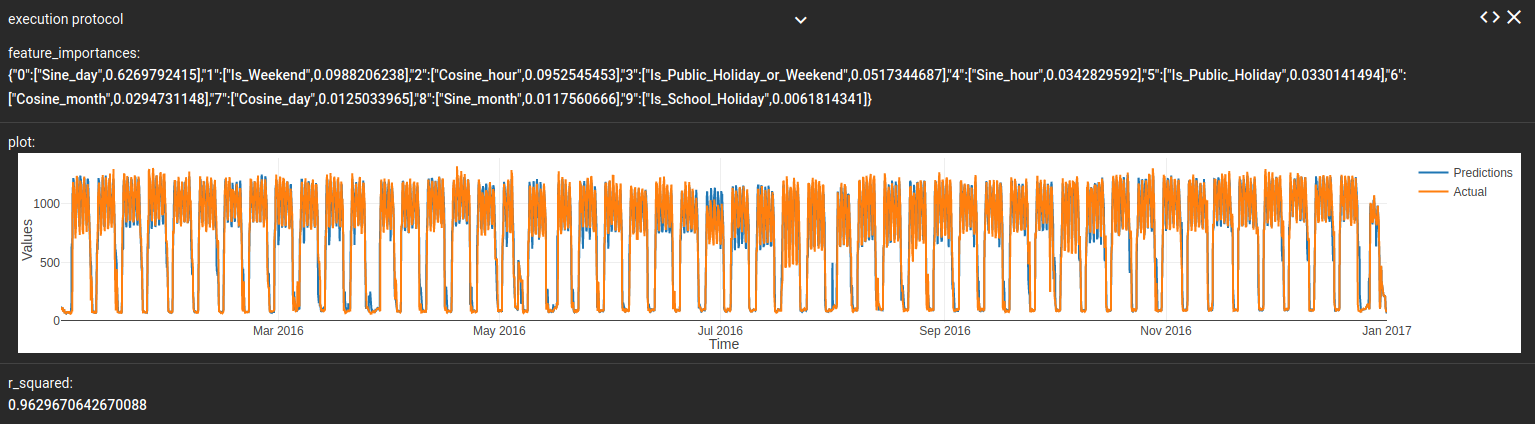
Abbildung 8: Das Ergebnisprotokoll nach Ausführung des obigen Workflow.
Der Wochentag hat den mit Abstand größten Einfluss auf den Stromverbrauch. Aber auch Wochenende, Schulferien und Feiertage zeigen signifikante Einflüsse, die bei einer Vorhersage zu berücksichtigen sind. Der R²-Wert liegt nun bei 0.96, konnte somit durch Übergang von der Linearen Regression auf den Random Forest noch deutlich verbessert werden. Der Random Forest ist also eine geeignete Grundlage für den Blick in die Zukunft.
Ergebnis: Vorhersage für den 25. Mai 2017
Zoomen wir in der Visualisierung des Lastgangs aus dem Jahr 2016 auf die Woche rund um den 25. Mai, so erhalten wir einen gewohnten Anblick. Eine fünf Tage Woche mit gleichbleibender Struktur, umrahmt von Wochenenden mit niedrigerem Verbrauch.
Für die Vorhersage, basierend auf dem Random Forest Algorithmus, generieren wir zunächst einen Datensatz für das Jahr 2017, in dem wiederum Abhängigkeiten von Wochentag, Uhrzeit, Feiertag und Schulferien integriert sind. Nun verwenden wir den Random Forest Algorithmus, trainiert auf den Daten des Jahres 2016, zur Vorhersage auf den Daten des Jahres 2017.
Abbildung 10: Workflow der Vorhersage für das Jahr 2017. Der Random Forest Algorithmus wird wie oben auf den Daten des Jahres 2016 trainiert. Parallel wird in der Komponente “Time Data“ ein Datensatz für 2017 erzeugt, für unser Unternehmen über die Eingabe “country = CH, province = AG, state = None, year = 2017“. Dieser wird dann zur Vorhersage an den Random Forest übergeben.
Können wir die Werte aus dem Jahr 2016 (Abbildung 9) einfach für das Jahr 2017 übernehmen? Ein Blick auf den Plot der vorhergesagten Verbrauchswerte zeigt ein anderes Bild! Am Donnerstag, den 25. Mai, fällt der vorhergesagte Verbrauch schlagartig ab. Der darauffolgende Freitag zeigt zwar wieder etwas mehr Verbrauch an, jedoch immer noch deutlich unter dem eines “normalen“ Freitags. Woran liegt das?
Beim Blick in den Kalender zeigt sich, dass der 25. Mai 2017 ein Feiertag ist, Christi Himmelfahrt. An diesem Tag standen die Maschinen der Firma still. Am folgenden Freitag wird wieder gearbeitet. Es ist aber davon auszugehen, dass viele Mitarbeiter an diesem Brückentag Urlaub nehmen und das Unternehmen nicht auf voller Auslastung läuft, was zu deutlich geringeren Prognosewerten führt! Der Random Forest Algorithmus hat diesen Sachverhalt erkannt und seine Energieprognose automatisch entsprechend angepasst.
Ihr Ansprechpartner
Dr. Steffen Wittkamp
Seit 2015 betreut, konzipiert und entwickelt Dr. Steffen Wittkamp Data Science Projekte von der Potentialanalyse bis hin zur vollumfänglichen Prognoseplattform inklusive Model Life Cycle Management. Schwerpunkte sind dabei Operationalisierbarkeit und die Robustheit von Data Science Lösungen im täglichen Betrieb.